LiRI Corpus Platform (LCP)
LCP is a cloud-based solution for handling and querying small to large multimodal corpora developed and maintained by a team at LiRI, the Linguistic Research Infrastructure at UZH.
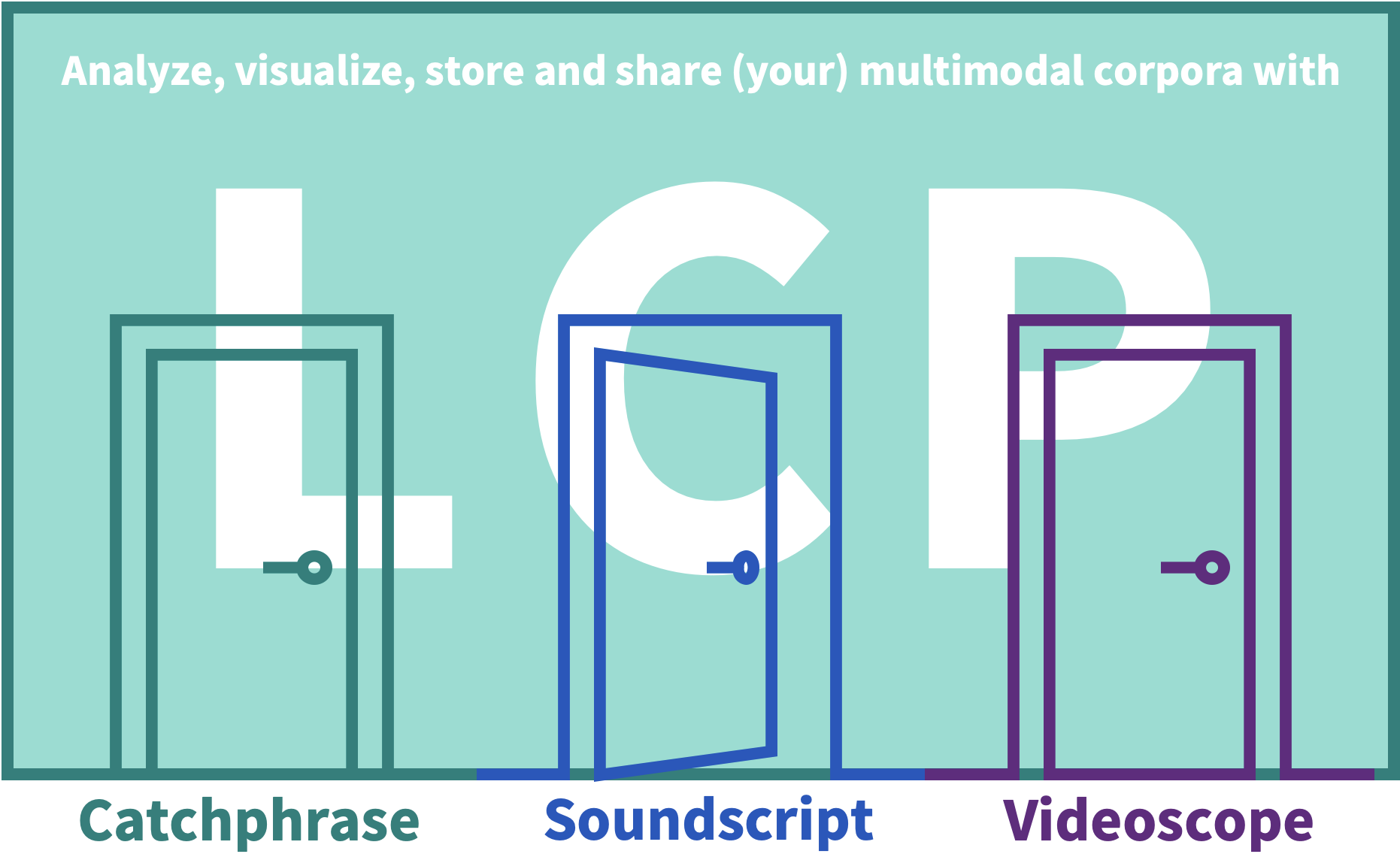
1. Catchphrase is the LCP interface optimized for working with text corpora: use it when you are working with mono- or multilingual text corpora of any size, or for faster inspection of the text content of audiovisual collections.
2. Soundscript is optimized for working with audio corpora: use it for speech corpora that include audio recordings, transcriptions, and any other annotations on the textual or media stream. Results will output text and sound recordings.
3. Videoscope is optimized for working with audiovisual/video corpora: use it for viewing and querying audiovisual corpora based on video, that can include annotations on the media stream or text. The interface includes a video player and a timeline annotation preview.
Corpora
Users can query corpora from their browser by accessing the public collections, or by importing their own corpora using a command-line interface. Currently, the following collections of corpora are publicly available in LCP:
Text corpora (catchphrase)
- British National Corpus (BNC) - English
- Text+Berg-Korpus - Alpine Journal - Swiss German, High German, Romansh, Italian, French, English
- NOAH's Corpus: Part-of-Speech Tagging for Swiss German - Swiss German
- What's Up Switzerland - Swiss German, High German, Romansch, French, Italian
- The Swiss SMS Corpus - Swiss German, High German, French, Italian, Romansh
Audio corpora (soundscript)
- OFROM - corpus Oral de Français de Suisse Romande - French
- ArchiMob - Swiss German
First steps
The publicly accessible corpora of LCP are listed at https://lcp.linguistik.uzh.ch.
The corpora are color-coded according to their modalities: green indicates text-only corpora, blue indicates audio corpora, and purple corresponds to video corpora. Those open, respectively, in catchphrase, soundscript and videoscope by default; (the text content of) audiovisiual corpora can also be open in catchphrase.
Clicking on the (i) icon of a corpus box brings up more information about the corpus, including the structure of its annotations, which differ across datasets. See more information on corpus structure here: Corpora in LCP.
Login: edu-ID
While public corpora do not require log-in, querying semi-private corpora (e.g. Sparcling) requires authentication. Authenticated users can also manage their own private collections of corproa.
The login button can be found in the top-right corner of the page. LCP uses the Switch edu-ID login system, which offers institutional authentication. If you cannot find your institution in any of the provided options, please create a new Switch edu-ID login.
Querying corpora
The Text query option lets users search for plain words or sequences of words in a corpus. Below are two side-by-side screenshots of a search and its results for the word Uftrag in the SWATCH annual report entry of the Swiss German NOAH's Corpus:
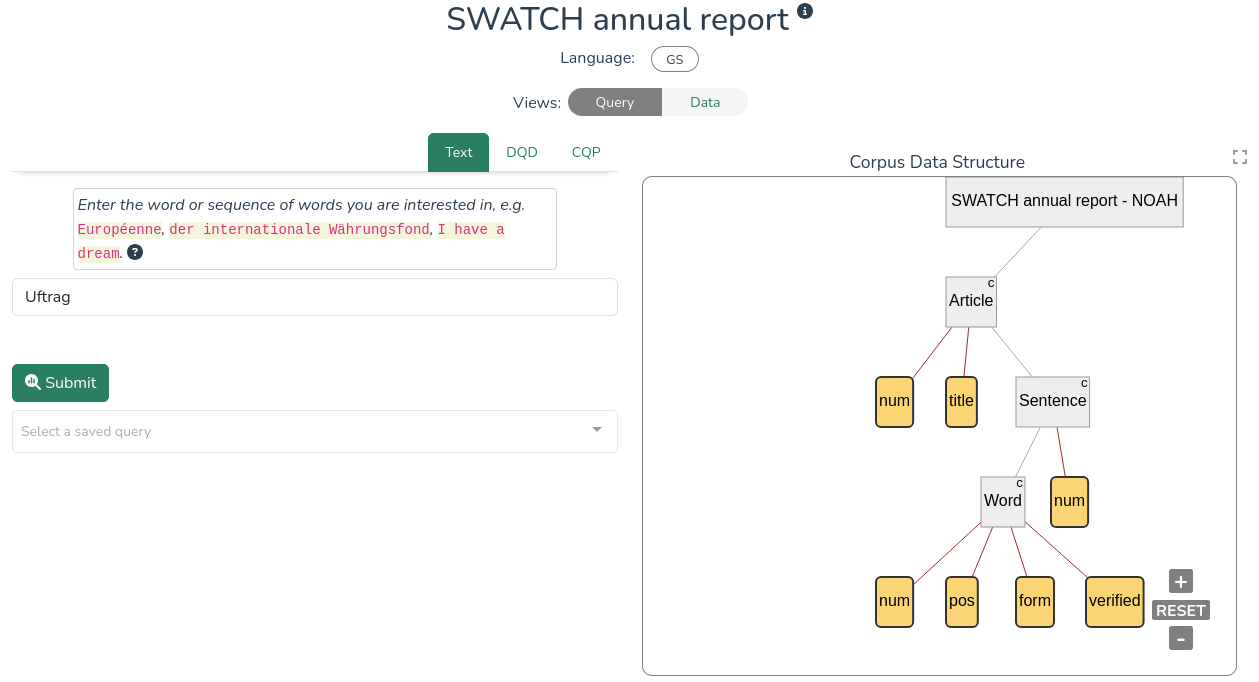
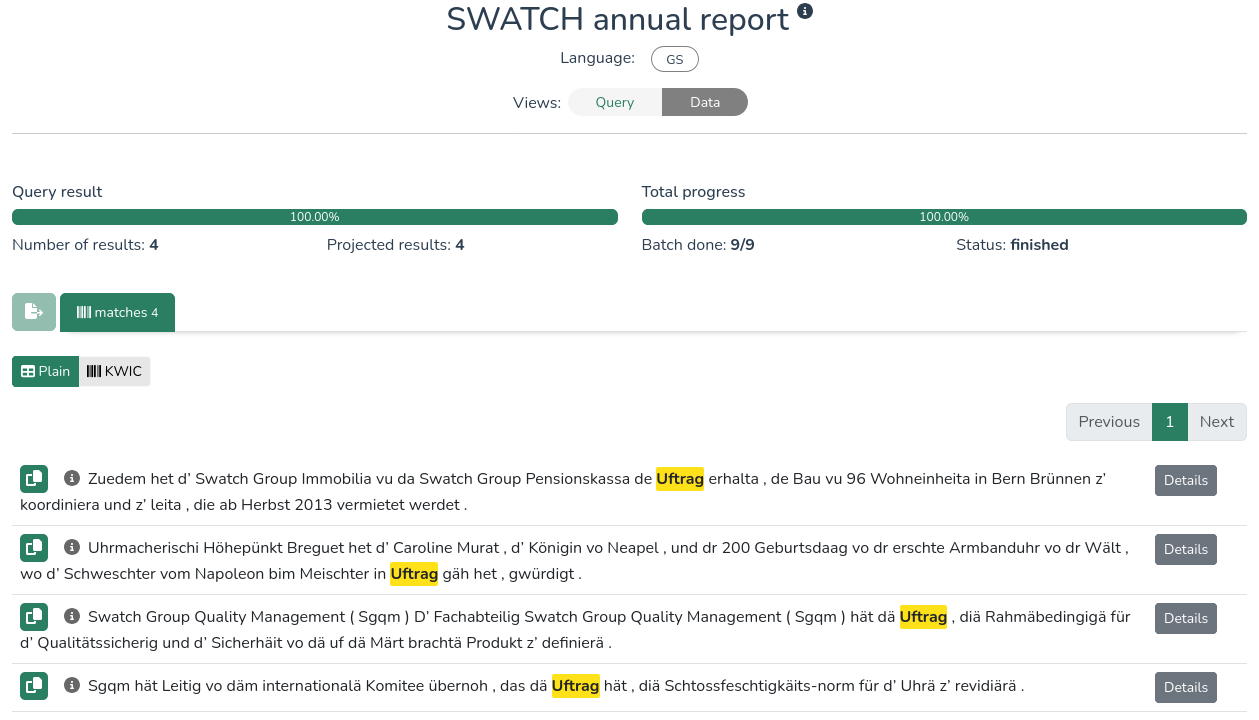
For more advanced searches, LCP uses a dedicated query language called DQD. LCP provides example queries for each corpus, with comments (highlighted in green) guiding the user through their first query. As you are getting to know the platform and query language, you are invited to play around with the existing queries and see how the results change. Once you have written a valid query, click Submit to run the query.
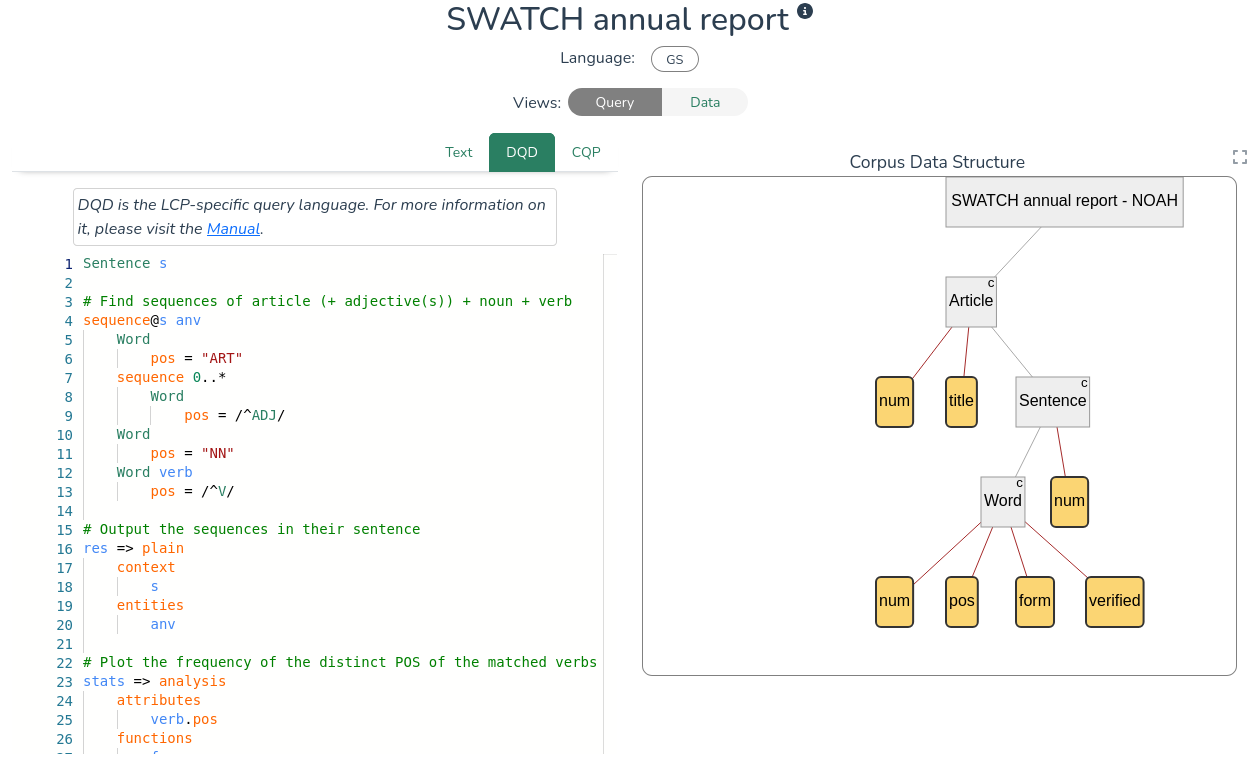
To learn more about querying options, see the Querying section. To learn more about the format of the results, see the Results page.
Beta-testing
LCP is currently in beta testing. The platform is free to use during this period, and we encourage users to provide feedback regarding discovered bugs or desired features via lcp@linguistik.uzh.ch.