Data & Sturcture
Corpora in LCP
In LCP, a corpus is modeled as connected layers: at least three layers must represent (i) ordered units, (ii) ordered collections of said units, and (iii) unordered collections of the latter. Prototypically, these three units correspond to words/tokens, sentences/utterances, and texts/documents.
Layers can have any number of attributes for annotation purposes, and corpus authors can define additional layers to model further embedding or dependency relations. This means that the smallest layer (i) may contain not just raw tokens, but also lemmas, POS tags, dependency grammar functions, morphological information, as well as arbitrary, user-defined features or metadata.
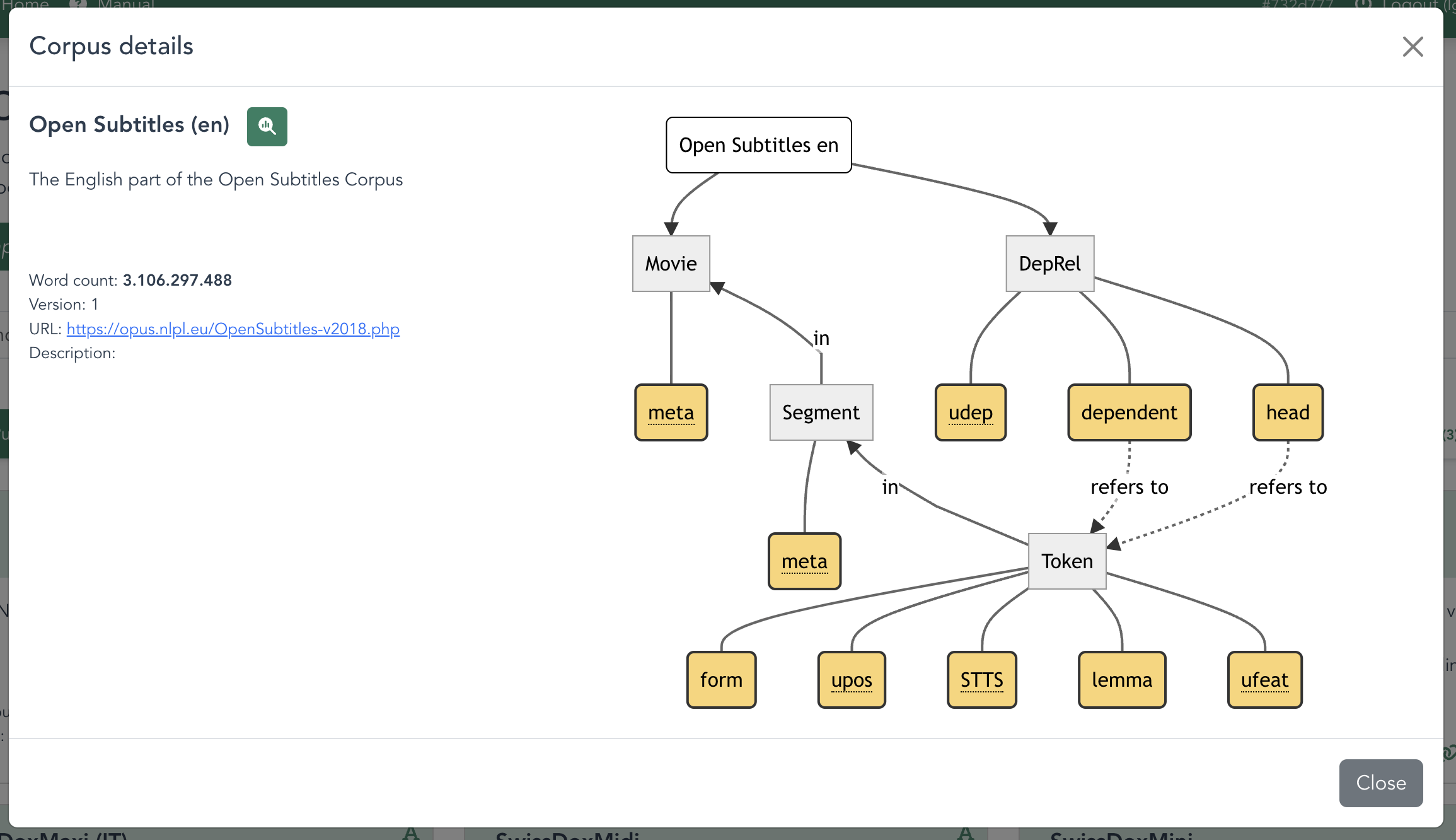
The diagram in the figure below shows the structure of a corpus created from the Open Subtitles corpus, which currently contains approximately ten billion words. Layer (i) represents individual tokens, each of which has a form, lemma and part-of-speech tag. Groups of these tokens comprise sentences (layer ii) which are themselves contained in movies (layer iii); a parallel layer models the dependency relations between tokens, allowing complex lexicogrammatical queries.
A simple command-line interface allows users to submit corpora to LCP as standard CSV tables along with JSON metadata (for private or public use). This data is converted and stored in a high-performance PostgreSQL database, making it possible to quickly query and obtain example sentences and statistical results from corpora containing billions of words.
Data Model
A key goal of LCP is to allow storage of very diverse corpora (simple and richly annotated; text-based and audiovisual; hundreds to billions of words) within a common structure, and to provide interfaces that allow querying these corpora for linguistic information via both web-browser and API. To that end, LCP models all corpora in a similar way. All data and annotations stored according to this data model are linearized and unambiguously positioned along at least one of three dimensions.
Dimensions
Annotations and data must be aligned along at least one of three dimensions:
- Text: traditional text corpora, comprised of (generally large amounts) of text data and annotations;
- Time: audio/video corpora, where words are positioned along a timeline;
- Space: multimodal corpora, where text is positioned on spatial coordinates, such as a position on a page.
These are explained in more detail below.
Textual dimension
An entity being aligned to the text dimension simply means that the entity has a textual representation - e.g. tokens in a conventional text corpus: LCP conceptually flattens all text in a corpus (= all text is concatenated into one large "string"), and gives each Token its single, unambiguous spot, that can be described by means of a start and end position in that text stream is computed. These positions allow for quick and simple comparisons between Tokens (e.g. does Token B follow Token A?), as well as other Layers that are textually anchored (e.g. 'does Document X contain Token A?').
Temporal dimension
Entities that can be temporally located are aligned relative to the time axis. E.g. in a video corpus with annotated gestures, each Gesture has an unambiguous start and end time point relative to the video (in fact, if the corpus contains several videos, then all videos are put in a (potentially arbitrary) sequential order and all entities are positioned relative to the global start point).
Spatial dimension
Lastly, entities can occupy a section on a 2-dimensional plane: E.g. on a scanned medieval document, each Token can be unambiguously located by its x- and y-coordinate.
It is important to understand that layers can have several anchorings: In a transcribed speech corpus, Tokens are located in the text dimension on the one hand, and they occupy also a position along the time axis (of course only if this time information has been annotated on the token level); thus, they can serve as a "link" between the two dimensions, and queries where purely temporal and textual entities are combined become possible: Show me all Tokens of form X that overlap with a Gesture Y.
Layers
A layer is an abstract class of things: Token is an example for a layer; it contains all instances of tokens. Through a layer definition, users can specify which attributes (see below) individual instances of it can or must have: E.g. a Token must always have form; or a Gesture must always have one of the types [X, Y, Z]. Layers are defined in the Corpus Template. Though arbitrary names can be used, we use Document for documents, Segment for sentence segments and Token for tokens in the examples. As a convention to distinguish between layer names and e.g. variables in DQD queries, layer names are expected to start with an uppercase character.
Attributes
Attributes are also defined in the Corpus Template and thus their naming is for a corpus creator to define. As a standard set, we use form for word forms, lemma for lemmas, upos for Universal part-of-speech tags, and morph for Universal features. Attributes stored as Meta Data are mapped to regular attributes unless a native attribute with the same name exists. In that case, the meta attribute needs to be explicitely referenced.